
{kind=link}

- Geschwindigkeit bis zu 25 ppm (50 ipm Duplex)
- 20-Blatt-Dokumentenzuführung und eigener Steckplatz für laminierte
- Wi-Fi und Wi-Fi Direct
- Automatisches Scannen
- Scannen auf PDF, Datei, E-Mail-Server, Netzwerk, FTP, USB-Stick


| Synology DS220+ | Synology DS720+ | |
|---|---|---|
 |  |
|
| Stil | Gehäuse | Gehäuse |
| CPU | 2-core 2.0 (Basis) / 2.9 (burst) GHz | 4-core 2.0 (Basis) / 2.7 (burst) GHz |
| Unterstützte Laufwerke | 3.5" SATA HDD 2.5" SATA HDD 2.5" SATA SSD | 3.5" SATA HDD 2.5" SATA HDD 2.5" SATA SSD M.2 2280 NVMe SSD |
| Preis | 349,95 EUR | Preis nicht verfügbar |
| Bei Amazon kaufen ** | Bei Amazon kaufen ** |
Was ich in Berichten immer wieder am spannendsten empfinde, ist der Weg. Also wie sieht unser papierloser Alltag denn nun konkret aus? Ob ein System letztendlich überzeugen und sich über längere Zeit durchsetzen kann, ist stark von der Usablity der Lösung ab. Unser Paperless Workflow scheint sich jetzt schon durchzusetzen, da er wirklich einfach nutzbar ist und der Zugriff auf Dokumente ebenfalls intuitiv geschieht.
Scan von Rechnungen, Post und anderen Papierdokumenten
Unser Workflow startet beim Leeren des Briefkastens. Wir schauen uns die Briefe nach dem Öffnen natürlich an. Anschließend versuchen wir direkt die Post in Paperless zu digitalisieren. Schaffen wir das nicht, legen wir die physischen Dokumente zumindest schon einmal in die Ablage neben dem Scanner ab.

Schnelltasten am Brother ADS-1700W
Um den Arbeitsablauf an dieser Stelle für uns zu beschleunigen, habe ich die sogenannten Schnelltasten des Brother ADS-1700W ** konfiguriert. Wie ihr sehen könnt, nutze ich jeweils ein Profil für das Scannen in Farbe und in Graustufen und zwar in Duplex sowie jeweils ein Profil für das Scannen von Inhalten, die nur auf der Vorderseite bedruckt sind. Mittlerweile hat sich herausgestellt, dass wir nur die ersten beiden Profile nutzen. Der Grund dafür ist, dass die automatische Leerseiten-Erkennung des Brother Scanners wirklich gut funktioniert.
Kopieren von digitalen Dokumenten nach Paperless-ngx
OCR Scanner – QuickScan
Schreddern der Papierdokumente
- Zweck: Überlegt euch, wofür ihr den Schredder verwenden möchtet. Möchten ihr hauptsächlich Papier schreddern oder sollen auch CDs/DVDs, Kreditkarten oder andere Materialien zerkleinert werden? Es gibt Schredder, die speziell für Papier ausgelegt sind, während andere auch andere Materialien verarbeiten können.
- Fassungsvermögen: Bedenkt, wie viel Papier ihr in der Regel schreddern müsst. Dabei kann ein Schredder mit einem größeren Fassungsvermögen effektiver sein und euch Zeit sparen, ist jedoch in der Regel auch teurer.
- Schnittleistung: Achtet darauf, dass der Schredder über eine hohe Schnittleistung verfügt, um Papier effektiv zu zerkleinern. Eine Schnittleistung von mindestens 6-8 Blatt Papier pro Durchgang ist in der Regel ausreichend für den häuslichen Gebrauch.
- Sicherheitsmerkmale: Der Schredder sollte gewisse Sicherheitsmerkmale wie automatische Abschaltung bei Überlastung oder Berührungssensoren besitzen. Dadurch können Unfälle bereits im Vorfeld ausgeschlossen werden. Gerade in Haushalten mit Kindern sollte dieses Merkmal besondere Beachtung finden. Unsere Kids bspw. lieben schreddern – bleibt dabei bitte stets in der Nähe.
- Größe und Gewicht: Bedenkt, wo ihr den Schredder aufbewahren wollt und ob ihr ihn immer wieder bewegen müsst. Es gibt Schredder in verschiedenen Größen und Gewichten, die sich für unterschiedliche Bedürfnisse eignen. Wir räumen den Schredder bspw. einmal in 14 Tagen aus dem Abstellraum heraus zum Akten vernichten.
- Preis: Bedenkt beim Preis immer, dass günstigere Schredder möglicherweise nicht so langlebig oder leistungsfähig sind wie teurere Modelle. Wir können aktuell den Amazon Basics Aktenvernichter wärmstens empfehlen. Dieser ist bei uns nun schon seit 2 Jahren ohne Probleme im Einsatz.

- Aktenvernichter für Papier und Kreditkarten, Partikelschnitt, bis zu 5-6 Blatt
- Sicherer Partikelschnitt mit einer Größe von 4 x 12 mm, Sicherheitsstufe 4
- Autostart-Funktion, praktischer Hebegriff und Überlastungsschutz
- 15,5-Liter-Eimer
- Thermo-Schutz schützt vor Überhitzung; Überhitzungs-Indikator
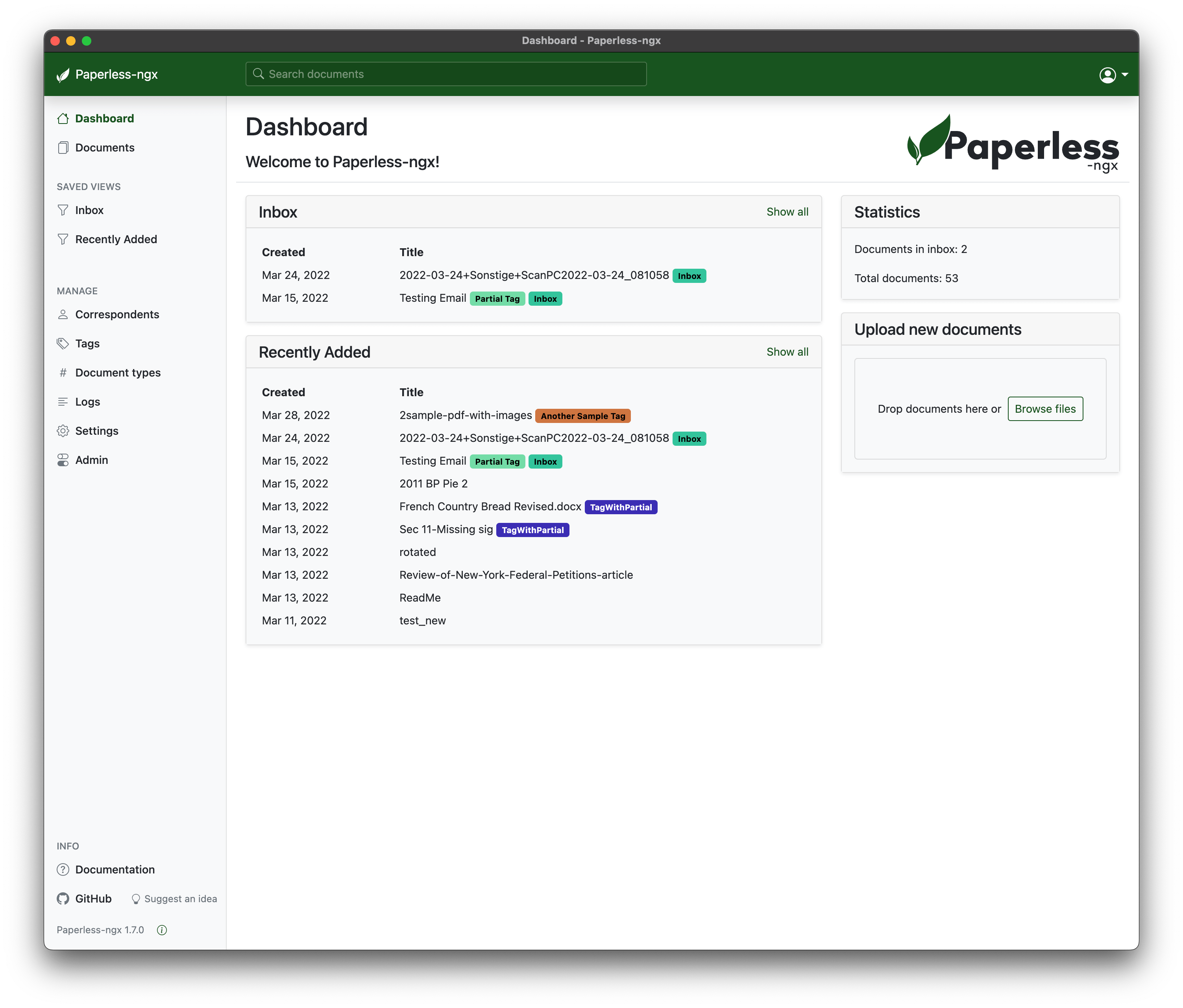
Ordnerstruktur im Docker Verzeichnis erstellen
Sind Docker und Portainer im Synology NAS installiert, müssen die benötigten Ordner für Paperless angelegt werden. Dazu öffnet die Synology Oberfläche und ruft die File Station auf. Wechselt nun in das Verzeichnis für Docker und legt folgende Ordner an:
- paperdb
- paperedis
- paperlessngx
- consume
- data
- export
- media
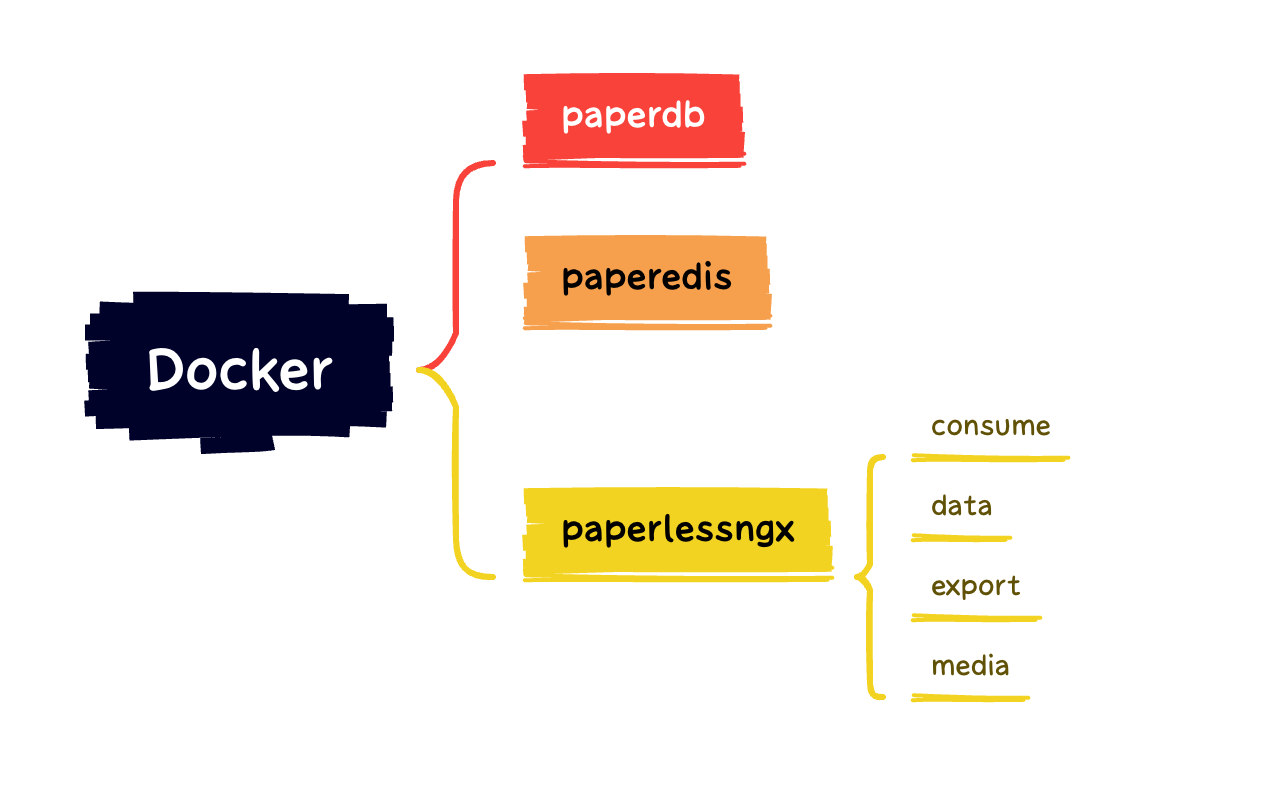
Ordnernstruktur für Paperless-ngx
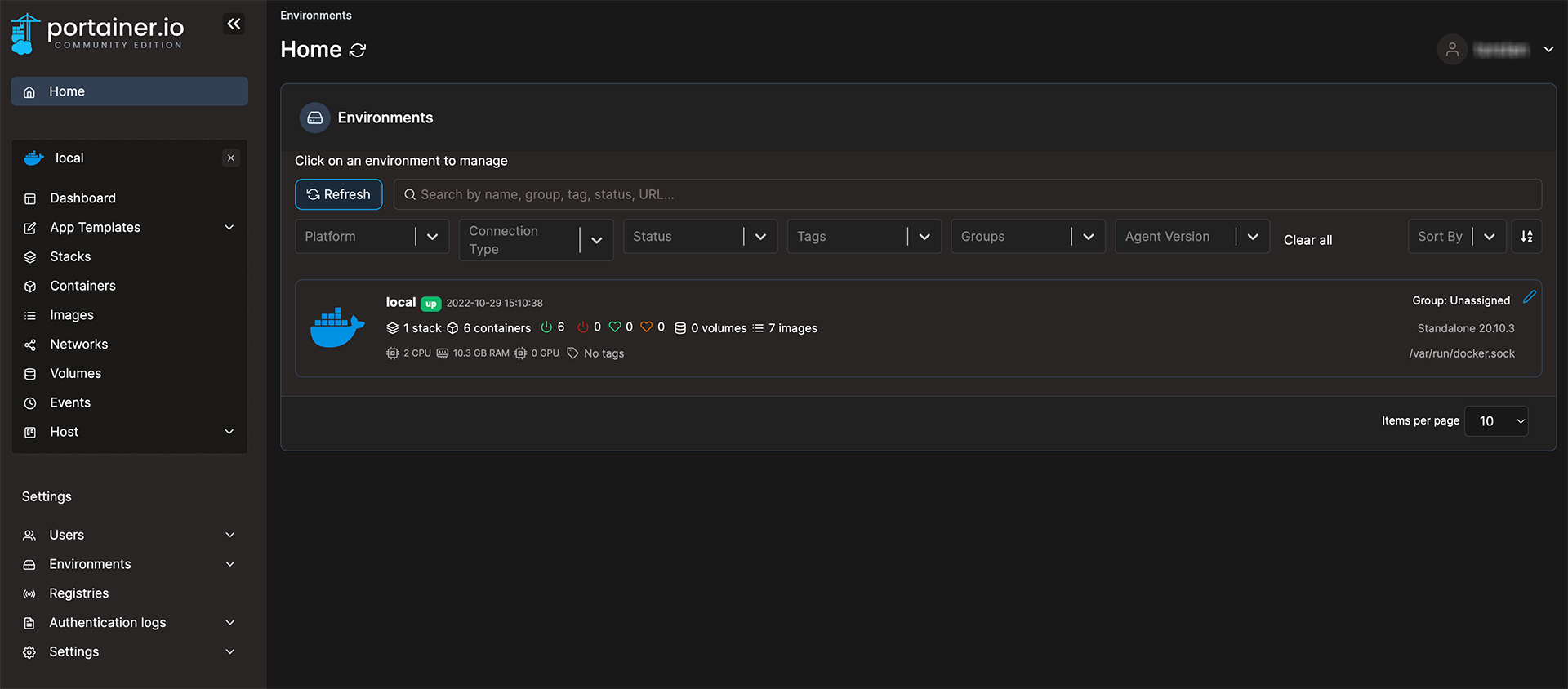
Paperless Stack in Portainer anlegen
Nun wechseln wir zum eben angelegten Portainer. Ruft dazu die von euch hinterlegte Adresse und Port auf. Sollte die Installation oben problemlos verlaufen sein, solltet ihr diesen Login nun sehen.
Portainer.io Login Screen
Im nächsten Schritt wird der Portainer Stack angelegt. Klickt dazu auf der linken Seite im Menu auf den Punkt “Stacks” und wählt dann “Add stack”.
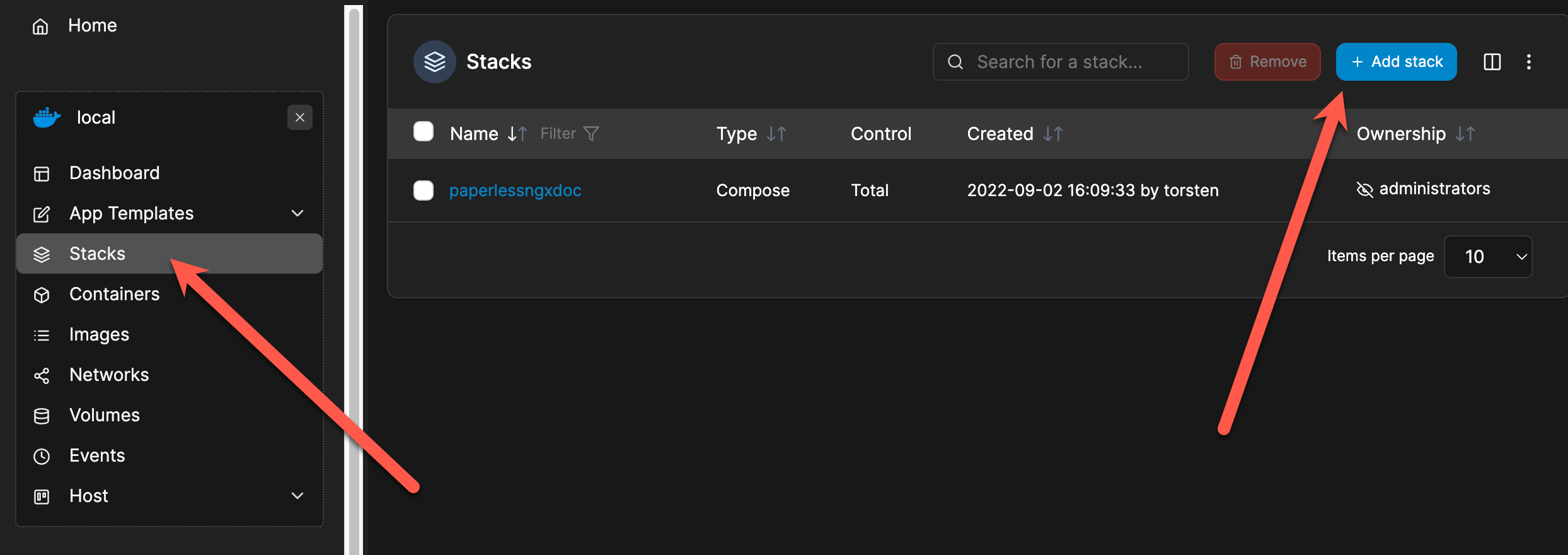
Portainer.io – Stack anlegen
Im nachfolgenden Dialog muss ein Name für den Stack vergeben werden. Wählt hier einen passenden Titel. Standardmäßig ist der “Web editor” als Build Methode bereits hinterlegt. Kopiert hier das unten aufgeführte Skript hinein.
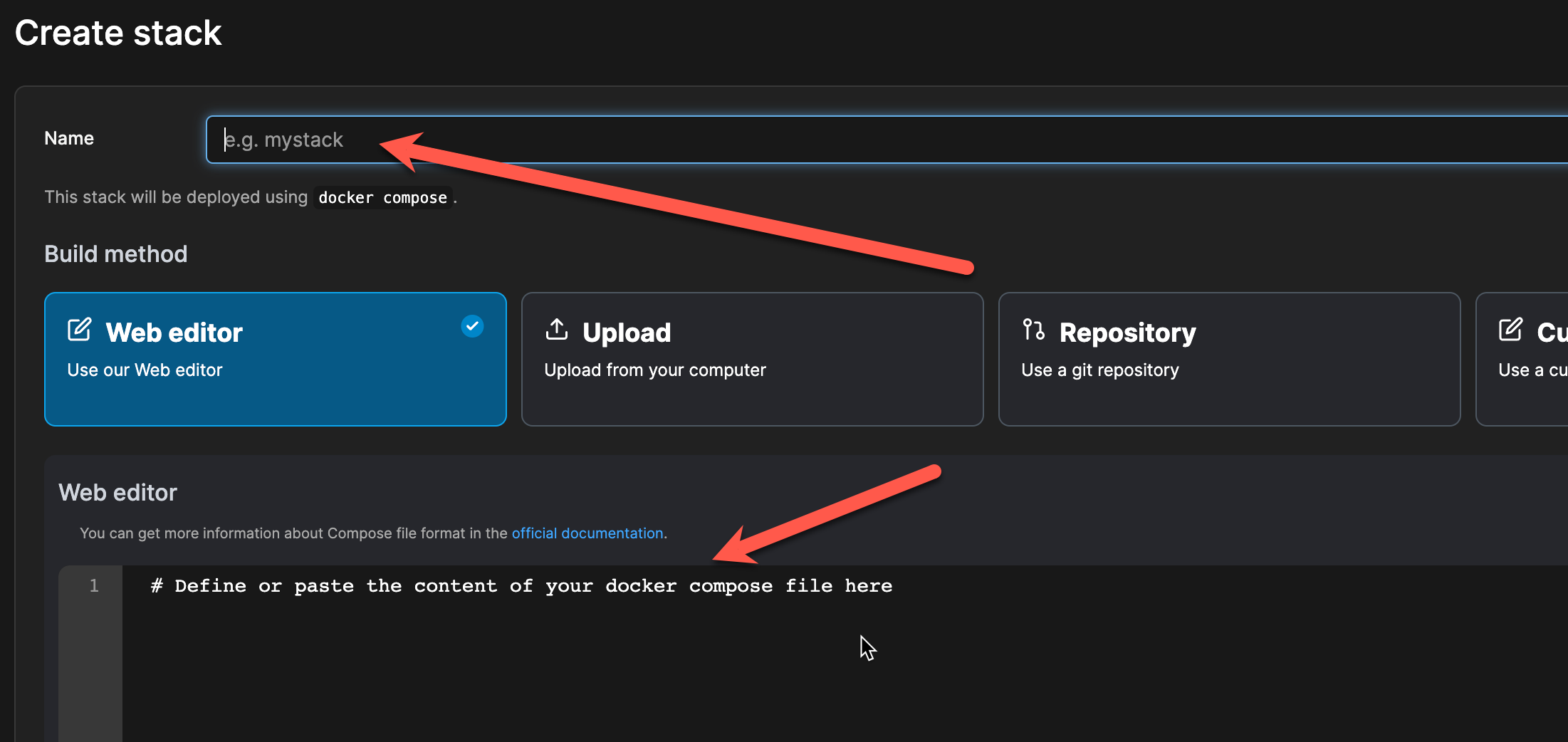
Portainer.io – Web editor im Stack anlegen
Ändert dabei unbedingt die rot markierten Stellen im Skript auf eure Umgebungsvariablen. Unter dem Skript findet ihr meine Hinweise dazu.
services: redis: image: redis:6.2 container_name: paperless-redis restart: always volumes: - /volume1/docker/paperedis:/data
db:
image: postgres:14
container_name: paperless-db
restart: always
volumes:
- /volume1/docker/paperdb:/var/lib/postgresql/data
environment:
POSTGRES_DB: paperless
POSTGRES_USER: paperless
POSTGRES_PASSWORD: paperless
webserver:
image: ghcr.io/paperless-ngx/paperless-ngx:latest
container_name: paperlessngx
restart: always
depends_on:
- db
- redis
- gotenberg
- tika
ports:
- 8777:8000
volumes:
- /volume1/docker/paperlessngx/data:/usr/src/paperless/data
- /volume1/docker/paperlessngx/media:/usr/src/paperless/media
- /volume1/docker/paperlessngx/export:/usr/src/paperless/export
- /volume1/scans:/usr/src/paperless/consume
environment:
PAPERLESS_REDIS: redis://redis:6379
PAPERLESS_DBHOST: db
USERMAP_UID: 1027
USERMAP_GID: 100
PAPERLESS_TIME_ZONE: Europe/Berlin
PAPERLESS_ADMIN_USER: EUER USERNAME
PAPERLESS_ADMIN_PASSWORD: EUER USER PASSWORD
PAPERLESS_URL: https://paperless.EURE REVERSE PROXY ADRESSE
PAPERLESS_ALLOWED_HOSTS: https://paperless.EURE REVERSE PROXY ADRESSE
PAPERLESS_OCR_LANGUAGE: deu+eng
PAPERLESS_TIKA_ENABLED: 1
PAPERLESS_TIKA_GOTENBERG_ENDPOINT: http://gotenberg:3000/forms/libreoffice/convert#
PAPERLESS_TIKA_ENDPOINT: http://tika:9998
PAPERLESS_ENABLE_UPDATE_CHECK: true
gotenberg:
image: gotenberg/gotenberg:7.4
restart: always
container_name: gotenberg
ports:
- 3044:3000
- 3000:3000
command:
- "gotenberg"
- "--chromium-disable-routes=true"
tika:
image: ghcr.io/paperless-ngx/tika
container_name: tika
ports:
- 9998:9998
restart: always
Hinweise zu dem Skript:
- Gotenberg Version 7.4
- Ich erhielt immer wieder den Fehler 503 Server Error: Service Unavailable for url: http://gotenberg:3000/forms/libreoffice/convert#/forms/libreoffice/convert
- Dieser Fehler trat immer dann auf, sobald ich eine Office Datei (docx) hochgeladen habe.
- Vorerst konnte ich das Problem nur beheben, indem ich Gotenberg Version auf 7.4 festgezogen habe und nicht die latest (7.6) verwende.
- PAPERLESS_ENABLE_UPDATE_CHECK: true
- Diese Funktion ist sinnvoll um immer informiert zu bleiben, sobald es eine neue Version vorhanden ist. Paperless informiert euch dann visuell wie im folgenden Bild zu sehen:

- Diese Funktion ist sinnvoll um immer informiert zu bleiben, sobald es eine neue Version vorhanden ist. Paperless informiert euch dann visuell wie im folgenden Bild zu sehen:
- USERMAP_UID und USERMAP_GID
- Die User ID des NAS Users und die Grupen ID könnt ihr relativ einfach über SSH Zugriff herausfinden.
- Stellt sicher, dass SSH Zugriff in Synology aktiviert ist:

Synology Disk Station – SSH aktivieren
- Öffnet das Terminal und verbindet euch mit folgendem Befehl auf euer Synology NAS
ssh NASUSERNAME@NAS-IP -p22
- Nun gebt den Befehl id gefolgt von dem Nutzername ein
id NASUSERNAME
- Es sollte eine Ausgabe ähnlich dieser erscheinen
uid=1031(NASUSERNAME) gid=100(users) groups=100(users), 101(administrators)
- PAPERLESS_ALLOWED_HOSTS und PAPERLESS_URL
- ich betreibe Paperless via Reverse Proxy, so dass ich auch ohne VPN darauf zugreifen kann. Die URL des Reverse Proxys sollte hier hinterlegt werden.
Den Stack deployen

Paperless-ngx – Login Screen
- Paperless-ngx arbeitet mit einem Ordner zusammen, der als Event-Trigger für das Verarbeiten von Dokumenten dient. Im Klartext: Immer dann, wenn in diesem Ordner Dokumente landen, zieht sich Paperless-ngx diese und verarbeitet sie. Diesen Ordner nutze ich als Ziel für den Brother Dokumentenscanner.
Ich nutze für den Konsumentenordner einen Freigegebenen Ordner in Synology. Das hat den Vorteil, dass sich dieser vor allem in MacOS schön mounten lässt.
Die Schritte dazu sind nicht schwierig:
- Verbindet euch auf das Synology NAS
- Ruft Systemsteuerung auf und wechselt zu “Freigegebener Ordner”
- Im DropDown “Erstellen” -> “Freigegebenen Ordner erstellen” wählen
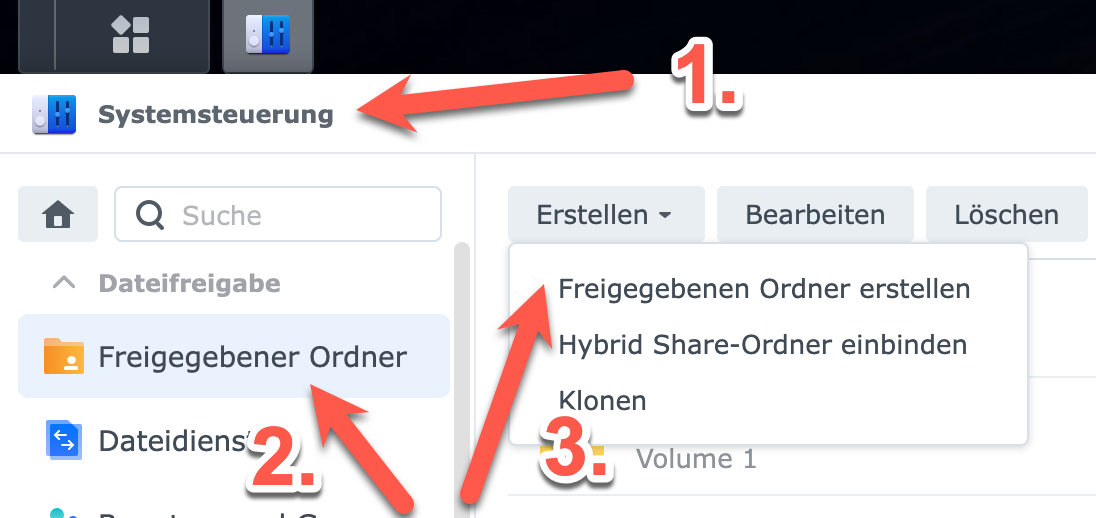
Synology Disk Station – Freigegebenen Ordner anlegen
- Name: einen Namen vergeben für den Ordner
- Die restlichen Checkboxen können im Standard belassen werden
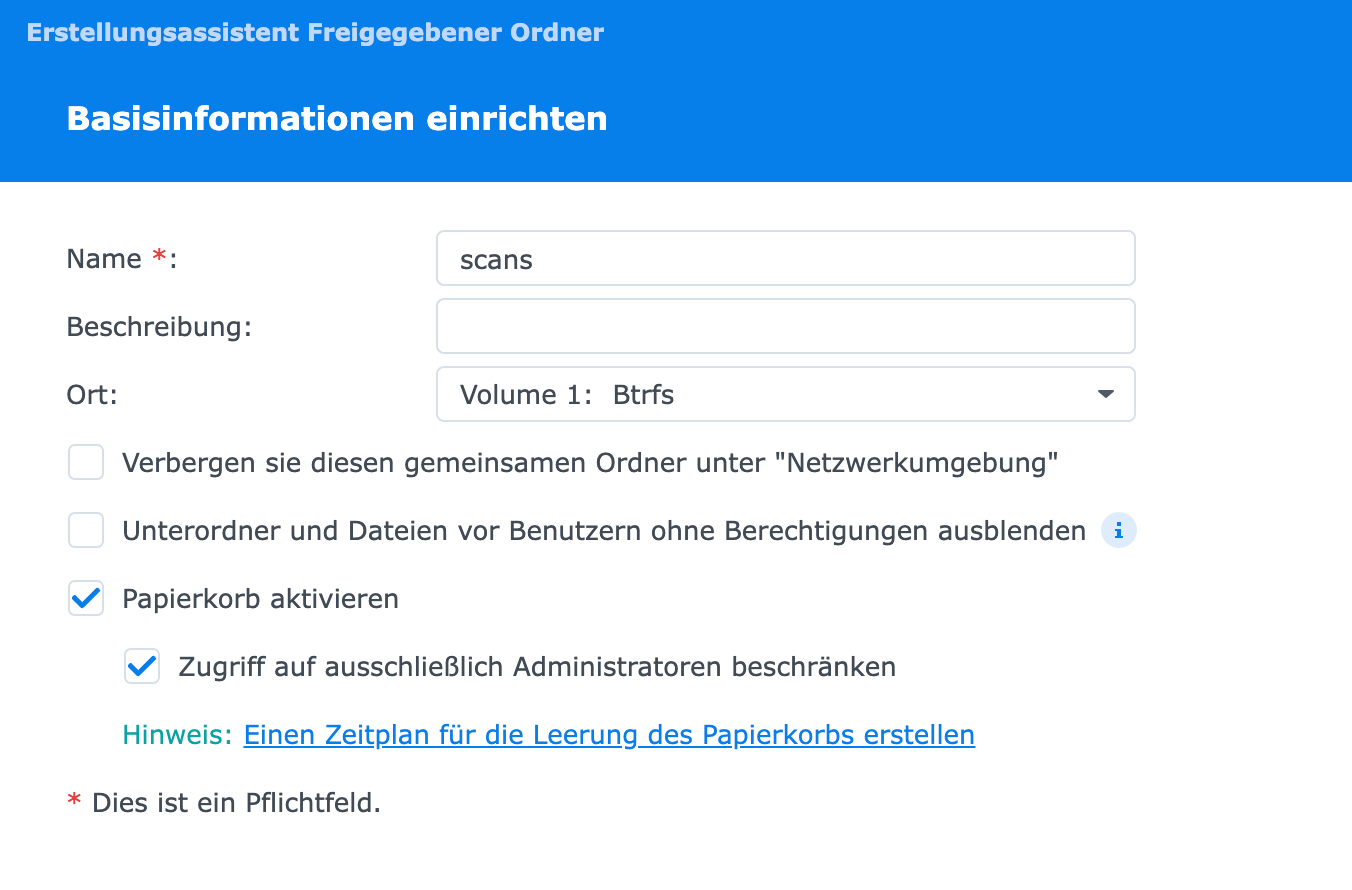
Synology Disk Station – Freigegebenen Ordner Details
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Nachdem nun das SSL-Zertifikat konfiguriert wurde, kann der Reverse Proxy angelegt werden. Dies kann in der Synology Systemsteuerung unter “Anmeldeportal” (1) konfiguriert werden. Unter dem Punkt “Erweitert” (2) ist die Konfiguration für Reverse Proxy zu finden (3). Nach einem Klick darauf zeigen sich alle, bisher angelegte Reverse Proxys. In diesem Dialog kann nun der Punkt Erstellen verwendet werden, um einen neuen Reverse Proxy zu erstellen (4). Übertragt nun eure Daten analog der in meinem Beispiel (5). Wichtig ist hier als Protokoll HTTPS zu wählen sowie Port 443 und für das Ziel den Paperless Port 8777 auszuwählen.
Nun sollte Paperless-ngx unter der Domain paperless.meineDomain.myds.me erreichbar sein – und zwar ohne Port. Denn für die korrekte Weiterleitung kümmert sich nun der Reverse Proxy.
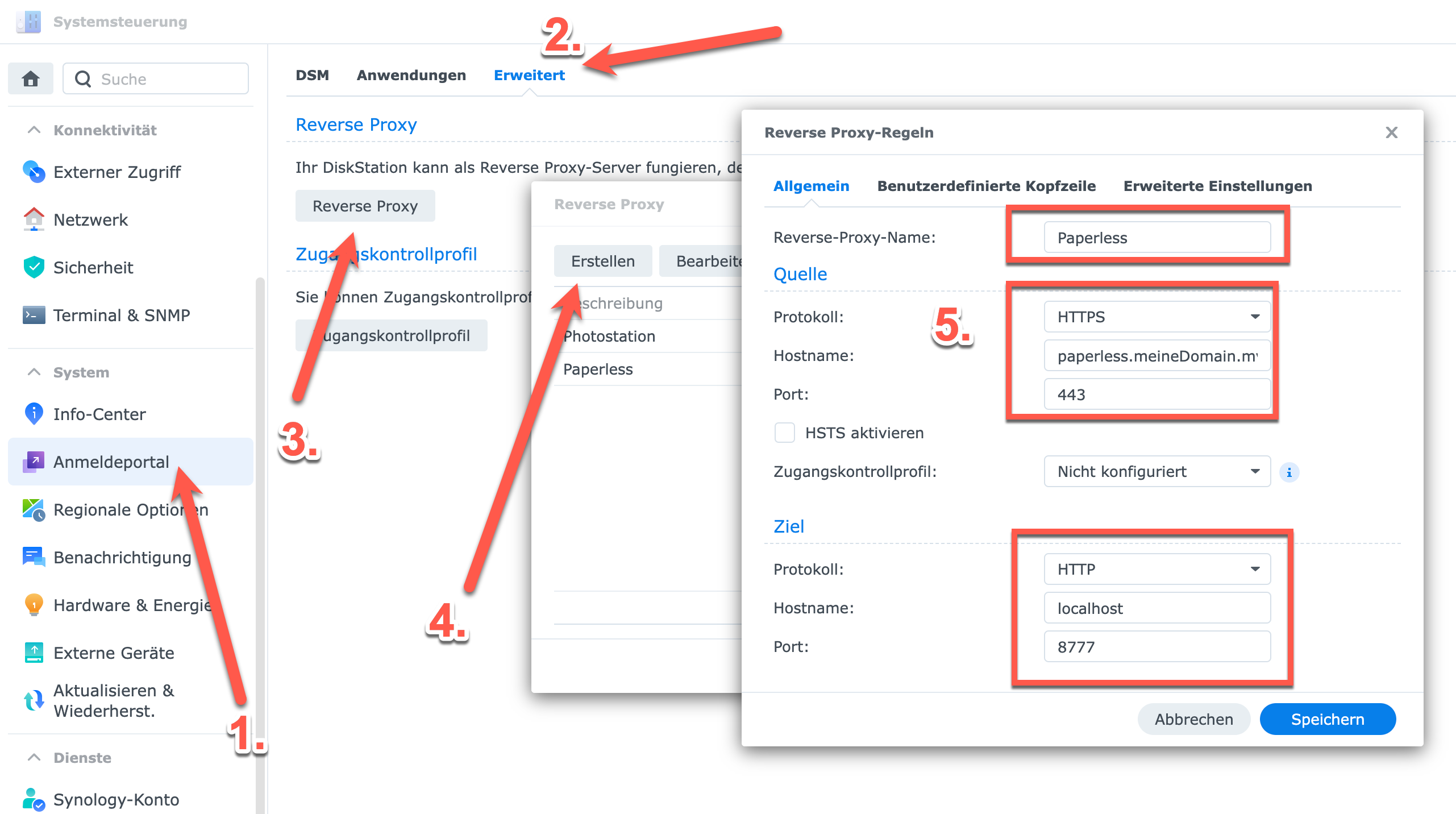
Synology Disk Station – Reverse Proxy anlegen
14 Kommentare
Vielen Dank für diesen Blogpost 🙂
Eine kleine Anmerkung: Im Abschnitt “USERMAP_UID und USERMAP_GID” fehlt nach dem Login via ssh der Befehl “id”, mit dem man dann letztendlich erst die uid, gid, groups & Co. angezeigt bekommt.
Vielen Dank Dominik – ändere ich 🙂
Ich erhalte nach Kopieren des Scripts für Portainer folgenden Error, und kann deshalb den Stack nicht deployen 🙁
There is an error in the yaml syntax: YAMLSemanticError: Map keys must be unique; “image” is repeated
EDIT: In dem hier hinterlegten Skript fehlen die Einrückungen! Wenn man die manuell korrigiert funktioniert das deployen. Das sollte man hier vielleicht entsprechend anpassen?
Hey Pascal,
danke für die Info. Welche Einrückungen meinst du genau? Vermutlich liegt das hier am Kopieren und da ich kein Quellcode Viewer drin habe.
Hi! In dem Script für portainer, es müsste zB lauten
services:
-> Tab -> redis:
-> Tab -> Tab -> image:
Ich bekomme aber auch weiterhin das Ding nicht zum laufen. Das Deployment klappt zwar, aber das Webinterface ist einfach nicht erreichbar unter der IP und mit dem angegebenen Port. VIelleicht muss man in der Fritzbox noch was umstellen? Oder sonstige Einstellungen im NAS?
Hallo Pascal, Du darfst im Yaml keine Tabs benutzen, Nur Leerzeichen!
Gruß Siggi.
Hi Torsten, kannst du nochmal erklären wie man den Drucker so einrichtet, dass er direkt auf einen Ordner auf dem Synology NAS scannt?
Bzw vielleicht kannst du auch die Details deiner Scan Profile zeigen (Einstellungen). Ich bin mit meinen Scan-Ergebnissen noch so gar nicht zufrieden…
Klar, dass kann ich machen … Aber hast du meinen zweiten Beitrag gesehen dazu? Da stehen die Settings drin.
Hallo Torsten. Kannst Du bitte erklären, wie ich den Consume-Ordner (mit voller Pfadangabe) so einstelle, dass er im Netzwerk auf einen anderen Computer führt? Ich möchte den Consume-Ordner auf einem anderen Gerät einrichten und nicht auf dem NAS, auf welchem Paperless NGX läuft… Liebe Grüße
Vielen Dank für diese umfassende und hilfreiche Anleitung. Sie hat mir bei der Einrichtung sehr weiter geholfen. Bspw. die Sache mit dem Stack. Habe ich lange versucht, die env-Parameter hinzubiegen bis mir klar wurde: den ganzen Stack editieren und wieder deploy… Habt ihr evtl. auch noch ein richtig gutes Backup am Start für die Konfiguration und sichert ihr die Dokumente nochmal extern?
“Denn sollte es sich um wichtige Dokumente handeln, die im Original benötigt werden, heften wir diese noch ab.”
Wie koordiniert ihr Paperless mit dem abgehefteten Original? Wenn ich das digitale Dokument gefunden habe, wie finde ich seinen physischen Zwilling? Das ist für mich aktuell (Dokumentenscanner, OCR, indizierte Dateien in eigener Projektstruktur) noch das größte Problem.
Ich kann da mal stellvertretend antworten… dafür vergibt man man Archivseriennummern, die man auch auf dem Dokument vermerken kann (handschriftlich, Aufkleber mit QR-Code, …). Die wird in Paperless hinterlegt, und dann heftet man das Dokument in einen Ordner der Wahl ab, der einfach aufsteigend sortiert ist. Sollte man dann doch mal ans Original müssen, klappt man den entsprechenden Ordner auf und findet dadrin das Dokument.